
News·
What is text classification and how does it work?
Text classification (or categorization) is one of the most common natural language processing (NLP) tasks. It consists in associating an unstructured text with a tag,
which corresponds to a specific class.

The only AI workspace you need
Text classification (or categorization) is one of the most common natural language processing (NLP) tasks. It consists in associating an unstructured text with a tag, which corresponds to a specific class.
If text categorization has a lot of hype, it is because of its numerous applications that go from sentiment analysis to spam detection through language detection and recommendation systems. In this article, we will discover what a classifier is, how it works and how one can implement one.
What is text classification?
Classifying is simply putting a label on a text, making it belong to a well-defined group or class.
Let's take the example of an application that offers the user the possibility to read articles on current events from different sources. Let's say we want to classify the articles by theme. We start by defining the possible themes: Sports, Politics, Economy, Health, and Technology.
The role of a classifier or classification tool, in our case, will be to "detect", for each article in the application, whether it is a sport, political, economic, health or technology article.
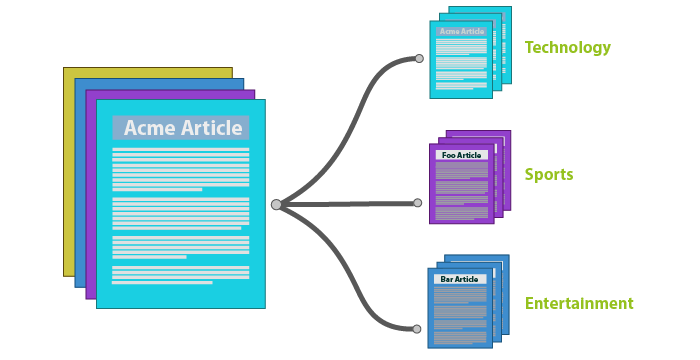 Text categorization is a generic concept, to say the least, and can, depending on the application and the needs, take on different forms. Here are a few of the best known:
Text categorization is a generic concept, to say the least, and can, depending on the application and the needs, take on different forms. Here are a few of the best known:
- Binary Classification: This is simply a 2-class classification. For example, a SPAM detection system classifies an e-mail as either "SPAM" or "NON-SPAM".
- Multi-Class Classification: This consists of associating text with one of several classes (more than two). As in the case of the news articles application mentioned above.
- Multi-Label Classification: This consists of associating the input text with one or more classes. For example, in the case of our news application, the same article could be in both the Economy and Technology categories.
- Cascade Classification: This is a classifier composed of several classifiers placed one after the other. The goal is to classify according to sub-classes.
How does a classifier work?
It is possible to implement a text classifier in several different ways. By using either:
A set of rules/keywords
This method simply consists in making an algorithm that respects certain rules. For example, we can make a list of keywords for each class. Let's say the classes are "Sport" and "Politics" and we want to classify the following sentences: "Cristiano Ronaldo is a Manchester United player" and "Joe Biden is the American President".
Our classifier will recognize the keywords "Ronaldo" and "Player" as being in the sports lexical field (and because they belong to the list of keywords corresponding to sports previously created).
And in the same way, the words "Biden" and "President" will also be recognized and therefore the sentence will be classified as "Politics".
Of course, one can implement much more complex rules than this example to make the classification more "intelligent". But the limitation of this method is that the classification is limited to the cases taken into account in the creation of the rules.
Moreover, it is a method that requires a lot of work, including rather laborious tasks, such as the creation of rules and lists of keywords.
Finally, this method is difficult to maintain, and scale.
A Machine Learning model
This approach consists in using Machine Learning techniques. In most cases, we will train a model with already classified data (or not) that serves as an example. Then use this model to classify new data. It is important here to identify the two steps that are training and inference.
One of the interests of a Machine Learning model is that we do not need to hardcode rules. The goal of training is to show examples to the model so that it automatically produces rules that will allow the classification of new data.
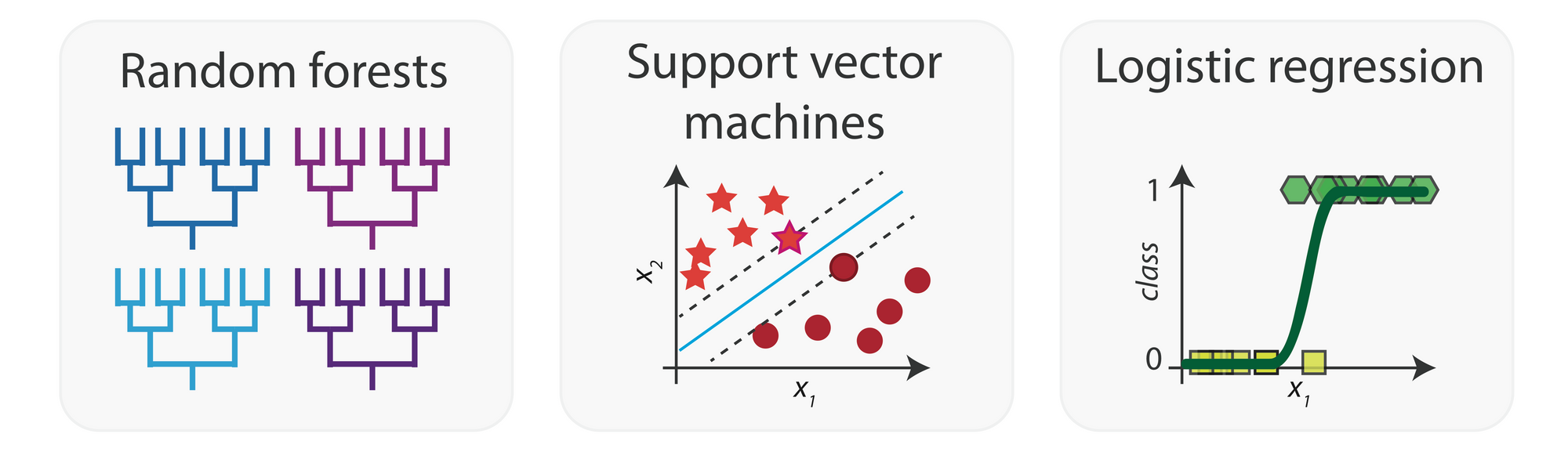 There are several machine learning algorithms that can be used to classify data (not only text) such as SVM, Random Forest, logistic regression, etc...
There are several machine learning algorithms that can be used to classify data (not only text) such as SVM, Random Forest, logistic regression, etc...
It is also possible to do Deep Learning by implementing a neural network.
In general, Machine Learning models produce much better results than rule-based classifiers. However, Machine Learning requires a certain amount of data, especially Deep Learning.
Tinq.ai classification API
In order to employ the methods outlined above, one needs extensive programming and data science skills.
Building classifiers doesn't need to be this hard. It is for this reason that through our extensive NLP API, we offer an easy-to-use classification service that one can implement in minutes without any programming knowledge.
[Video] Learn how to create custom classifiers with Tinq.ai in minutes.
Hybrid or mixed classifier
It is quite possible to create a text classifier that combines the techniques mentioned above. Indeed, we can add specific rules that will aim at "correcting" some shortcomings of the automatic models.
Conclusion
Text classification is a very important NLP task because of all the applications that can be derived from it.
There are several possible approaches to the realization of classifiers. Even if Machine Learning based models are generally more efficient than rule-based engines, it can be interesting to realize a mixed classifier.
Finally, we've seen that building an AI-based classifier can be a very tedious task. Leveraging API services like Tinq.ai to build powerful classifiers in minutes could be a great idea depending on the use case.
Tinq.ai's NLP API
Tinq.ai's mission is to make it easy for developers and non-technical people to have access to high-quality and easy-to-use machine learning tools.
We offer APIs for:
- Paraphrasing
- Summarizing
- Sentiment analysis
- Entity Recognition
- Web Article extraction
- Plagiarism checker
Feel free to register and try our tools for free.
Related Posts





Unify all your datasources and give your AI the context it needs.
Connect Google Drive, SharePoint, Notion, CRMs, wikis, and more—securely indexed and instantly usable in ChatGPT, Claude, Gemini, or any AI assistant.